PromQL
时序数据库
时序数据库(Time Series Database,简称TSDB)是专门用于处理时间序列数据的数据库。时间序列数据是一种按时间顺序排列的数据点集合,通常用于记录随时间变化的数据,如股票价格、气象数据、物联网设备传感器读数等。
^
│ . . . . . . . . . . . . . . . . . . .
│ . . . . . . . . . . . . . . . . .
│ . . . . . . . . . . . . .
│ . . . . . . . . . . . . . . . .
v
<------------------ 时间 ---------------->横轴表示时间(通常是连续的时间线),纵轴表示测量的数值。每个数据点都对应一个时间戳和相应的数值
数据
# HELP node_cpu_seconds_total Seconds the CPUs spent in each mode.
# TYPE node_cpu_seconds_total counter
# 指标名 特征、维度 值
node_cpu_seconds_total{cpu="0",mode="idle"} 4.583223844e+07
node_cpu_seconds_total{cpu="0",mode="iowait"} 1612.86每一个点称为一个样本(sample),样本由以下三部分组成
- 指标(metric):metric name和描述当前样本特征的labelsets;
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value): 一个float64的浮点型数据表示当前样本的值。
Metric 指标的格式通常如下
<metric name>{<label name>=<label value>, ...}
# 同一个数据 两个表达方式
api_http_requests_total{method="POST", handler="/messages"}
{__name__="api_http_requests_total",method="POST", handler="/messages"}指标类型
Prometheus 的数据均以时序数据(time-serries)的形式保存在TSDB。这些指标也有这细微的差别,有的为固定值,有的为持续增大等。因此Prometheus定义了四个不同的指标类型,Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。或这样理解
- Counter: 只增不减的单变量
- Gauge:可增可减的单变量
- Histogram:多桶统计的多变量
- Summary:聚合统计的多变量
Counter
只增不减。如常见的http_requests_total,若非系统重置,永远增加。(如自定义Counter类型指标时,建议使用_total结尾)
counter类型,结合时序数据的特点,非常容易就能记录时间发生的次数,了解趋势喝概率,比如
- 请求的数量
- 任务完成的数量
- 函数调用次数
- 错误发生次数
...
例,通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])查询当前系统中,访问量前10的HTTP地址:
topk(10, http_requests_total)Gauge
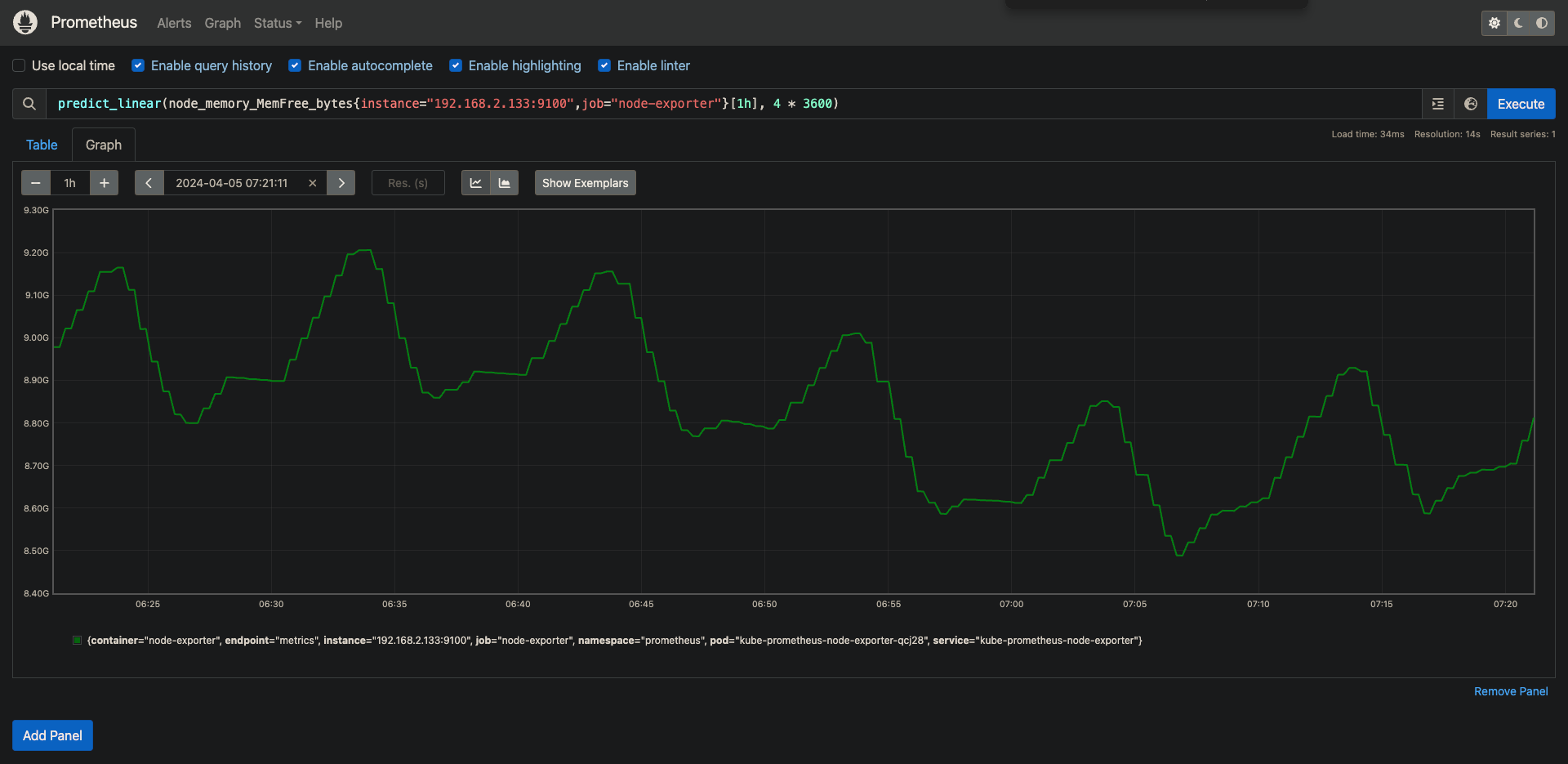
可增可减的数据,比如常见可用内存,已用内存等,均为gauge类型。比如: :node_memory_MemFree_bytes
对于 gauge类型的数据,可以通过内置的函数,获取指定指定时间范围的内数据,用来做计算,比如求平均值,求差,甚至趋势预测等,比如
- 温度
- 内存用量
- 并发请求数
...
使用predict_linear()对数据的变化趋势进行预测。例如,预测空闲内存,在4小时后的情况
Histogram
Histogram主用于统计和分析样本的分布情况。会对观测数据取样,然后将观测数据放入有数值上界的桶中,并记录各桶中数据的个数,所有数据的个数和数据数值总和。
以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
Histogram 类型的样本会提供三种指标:
- 样本的值分布在 bucket 中的数量,命名为 _bucket{le="<上边界>"}。解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。
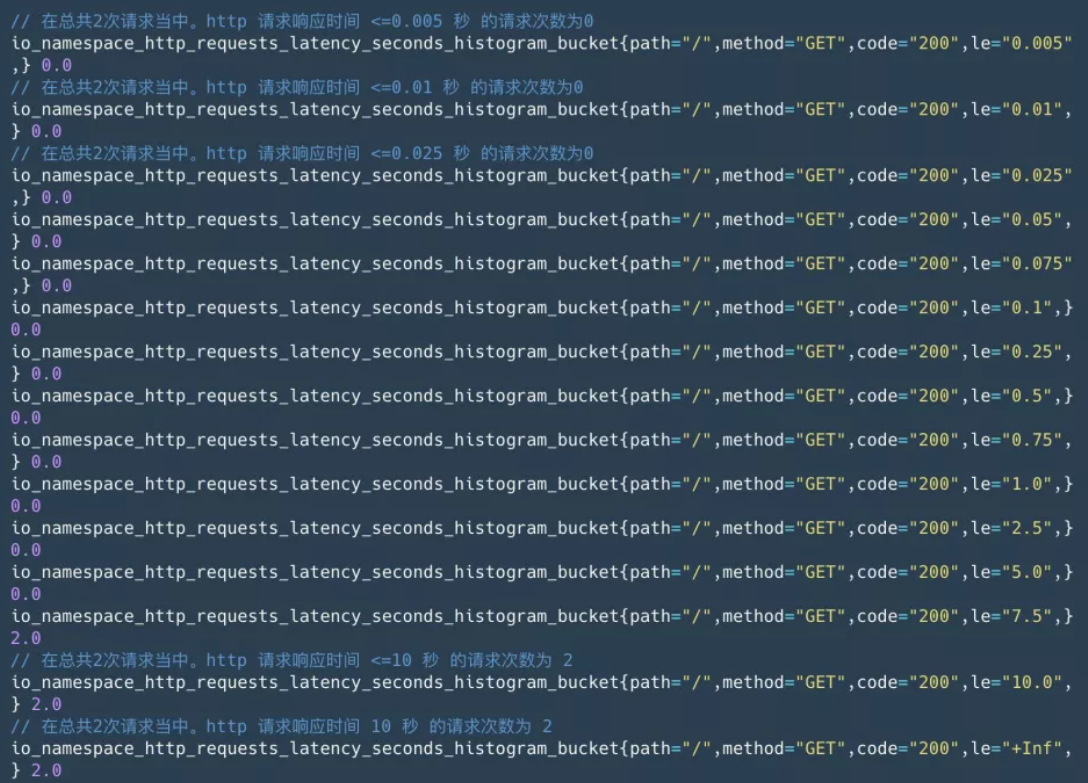
- 所有样本值的大小总和,命名为 _sum。
- 样本总数,命名为 _count。值和 _bucket{le="+Inf"} 相同。
Summary
与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。
summary的指标也分为三类(括号内以http请求为例)
- 样本总数,命名为 _count 。(一共发生了x次请求)
- 所有样本值的大小总和,命名为 _sum。 (x次的请求响应总和为多少)
- 样本值的分位数分布情况{quantile="分位数"} (有多少请求的响应,是在x毫秒)