向僵尸开炮-辅助脚本
背景
之前微信推送了一款名为向僵尸开炮的小游戏,前期玩的让我无法自拔,于是在忙碌中寻找片刻的悠闲。然而,游戏的内容显得过于单一,长久玩起来就有点枯燥了,还需氪金技术。因此,就渐渐的不再玩了。
数月后,再次打开了这个应用,发现我的体力值已经累积到了900多点。
这个游戏一局消耗:
- 5点体力
- 5-7分钟
- 20关卡,每一关需选择技能
简单算来,需要投入180局的精力。如果以每局五分钟计算,需要连续投入15个小时。
这么固定的操作,可不可以用自动化处理呢?说干就干!写个自动化脚本!
自动化
目前常见桌面自动化,主要分两种
- 操作浏览器的,通过获取浏览的元素,进行自动化操作,常见的自动化测试,多数都是这么干的,比如
seleniumplayWright - 操作鼠标,模拟人的行为。比如
pyatuoguitagui
当然,市面上还有比较成熟的厂商,已集成这两个功能,并且还支持挂脚本,可玩性更高,比如Uipath 影刀,Uipath好像更牛一些,前一段还推出单个机器人支持并发执行。
我的需求:支持PC,长时间挂机执行即可。
分析后的方案:pyatuogui+paddleocr
分析
分析下游戏界面。
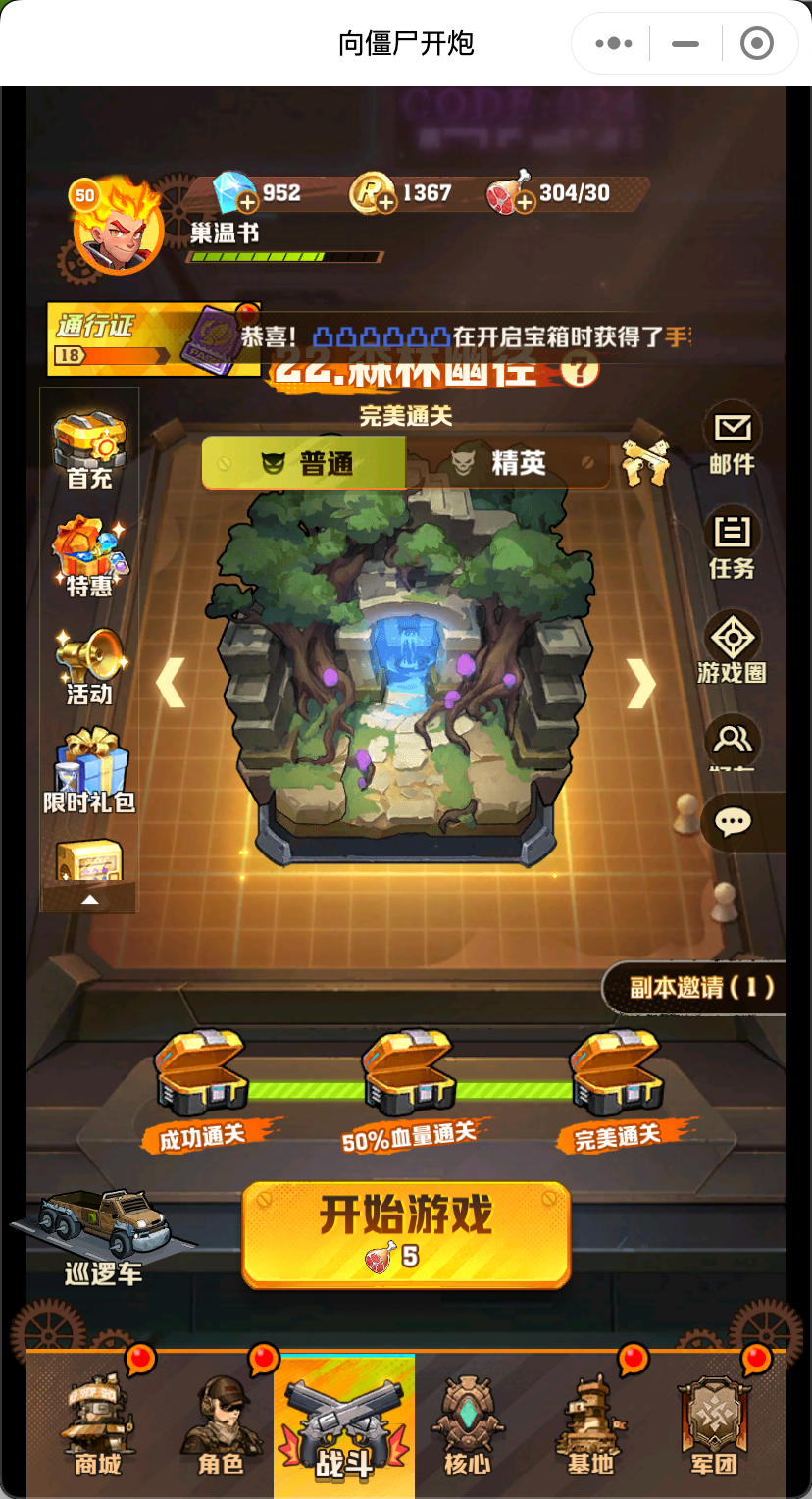
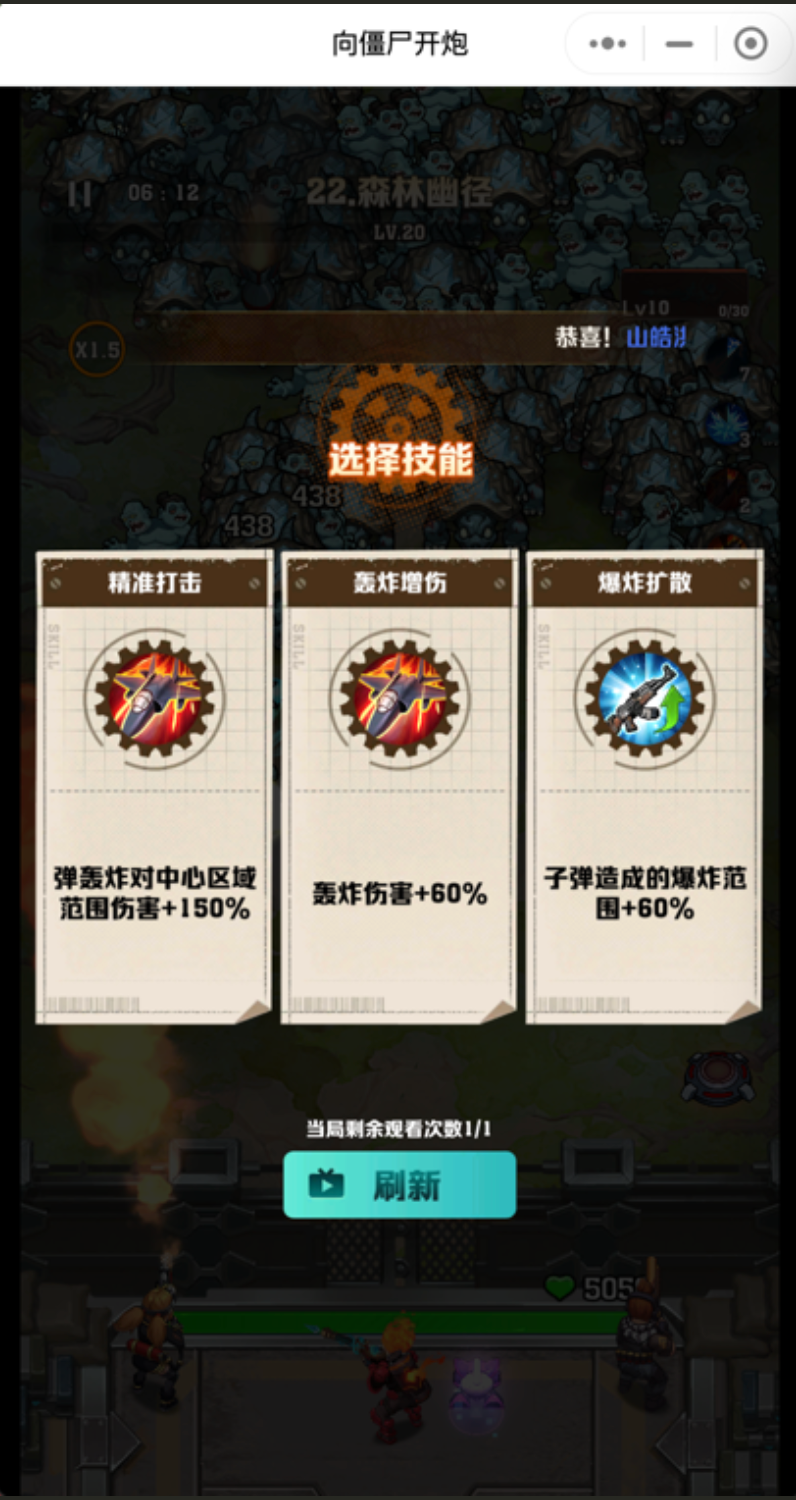
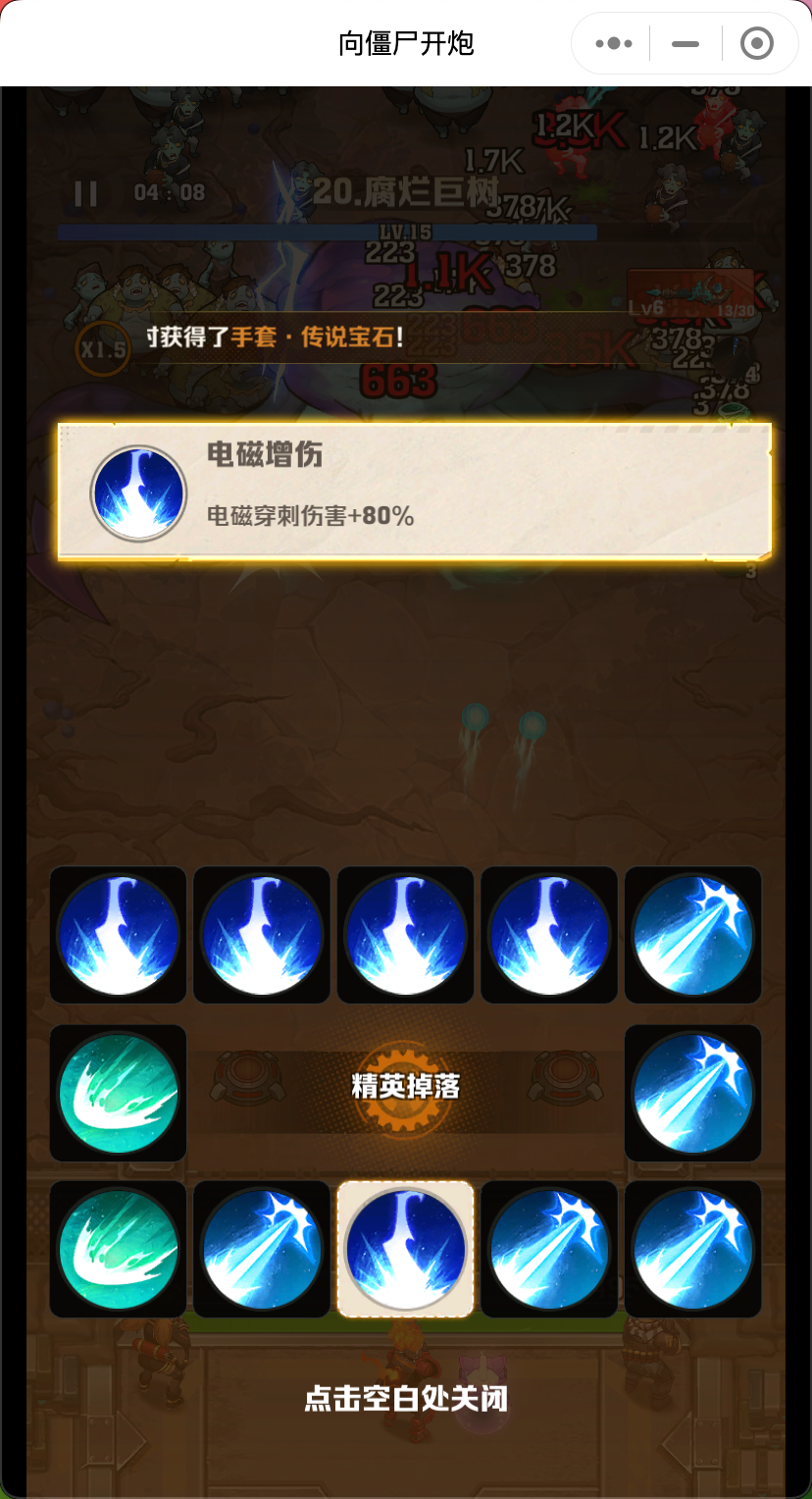
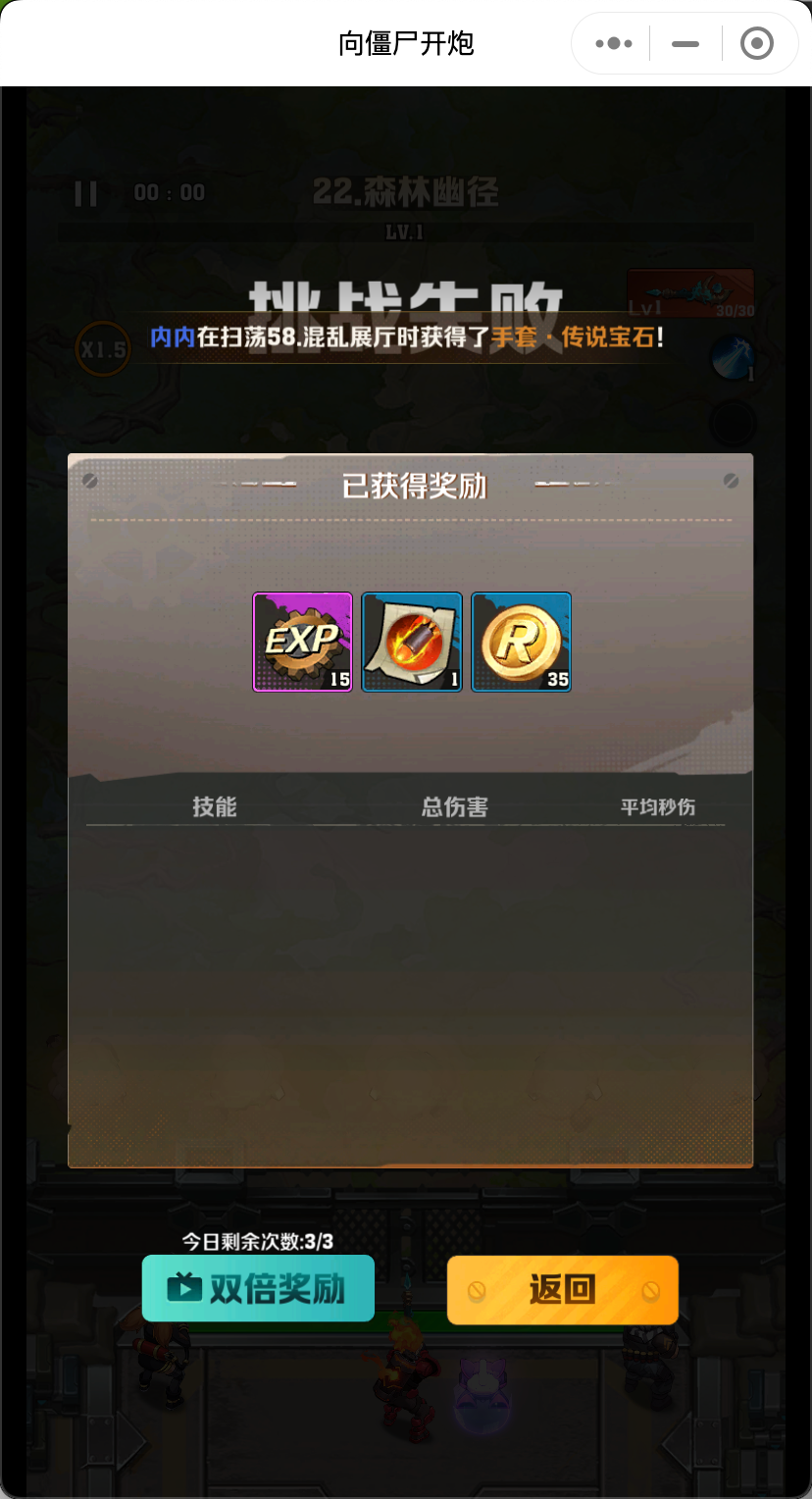
其实一局游戏的主要操作,就四步
开始游戏 技能选择 精英掉落 (失败/成功)返回 > 开始游戏 ..
设想的研发逻辑是: 截图 识别 定位 点击 > ..
实现
截图
Python平台有一个功能非常强大而且简单易用的图像处理库,Pillow。 可实现图像的转换、裁剪、缩放、旋转等操作。
使用pip直接安装
pip install pillowfrom PIL import ImageGrab
img = ImageGrab.grab(bbox=(left, top, right, bottom))
img.show()因为我有接扩展屏幕,所以还会有一个屏幕识别的问题,可以使用screeninfo库去解决
def screenshot_from_monitor(monitor_number=1,left=0,top=0,right=410,bottom=800,img_path="screen.png"):
monitors = get_monitors()
# print(monitors)
if monitor_number > len(monitors):
print("指定的显示器编号超出了实际连接的显示器数量。")
return None
# 截图指定区域 bbox代表截图的四个角的位置
screenshot = ImageGrab.grab(bbox=(left, top, right, bottom))
screenshot.save(img_path)坐标以函数参数的形式存在,也方便后续复用。这里写的简单,没做很多鲁棒性
识别
不必自己训练模型,使用已有的平台去做。paddleocr正好可以解决我们的需求。
具体安装不赘述,可进官网查看
https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/quickstart.md
def screenshot_orc(img_path):
ocr = PaddleOCR(use_angle_cls=True, lang='ch', use_gpu=False,show_log=False) # 默认使用英文和中文识别
# 进行 OCR 文本识别
result = ocr.ocr(img=img_path, cls=True)
# 获取识别后的坐标
boxes = [line[0] for line in result]
# 获取识别后的文字
txts = [line[1][0] for line in result]
return boxes,txts通过文字和坐标的获取,后续就可以去定位到我们想要的坐标位置,并进行点击操作了
定位
以最复杂的技能选择来说,首先我们要定义我们想要的技能列表,并排序好。通过列表的循环比对,就可以定位到我们想要的文字坐标。
## txts 是识别后的文字列表
if "选择技能" in txts:
# 技能优先排序定义
skill_to_find = [
"学习冰暴",
"子弹命中",
...
]
# 两个列表匹配,并定位index,通过index查找坐标位置
skill_index = find_skill_index(skill_to_find,txts)
if skill_index is not None:
# 执行点击操作
passdef find_skill_index(skill_to_find, skill):
for skill_needed in skill_to_find:
# 遍历skill列表中的每个元素 并查找,找到则返回index
for index, skill_available in enumerate(skill):
if skill_needed in skill_available:
return index
return None
# 生成随机坐标,并排除图片间空隙部分
def generate_random():
while True:
num = random.randint(60, 360)
if not (133 <= num <= 155 or 260 <= num <= 280):
return num点击
安装
pip install pyautogui这里主要用了两个功能,鼠标点击(click)和移动(moveTo),具体参考官网
def gui_clieck(x,y,clicks=2):
p = pyautogui.position() # 获取鼠标当前位置
pyautogui.click(x,y,clicks=clicks)
pyautogui.moveTo(p.x,p.y) # 返回鼠标指针代码
所有的功能都实现了,可以使用了。全部代码如下,还有非常多的优化点,鲁棒性也不够
#!/usr/bin python
# -*- encoding: utf-8 -*-
import os
import json
import time
import logging
import random
from PIL import ImageGrab
from screeninfo import get_monitors
from paddleocr import PaddleOCR, draw_ocr
import pyautogui
logging.basicConfig(format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s',
level=logging.INFO)
# level=logging.DEBUG)
# 屏幕截图
def screenshot_from_monitor(monitor_number=1,left=0,top=0,right=410,bottom=800,img_path="screen.png"):
monitors = get_monitors()
# 这里可以显示屏幕信息
# print(monitors)
if monitor_number > len(monitors):
print("指定的显示器编号超出了实际连接的显示器数量。")
return None
# 截图指定区域
screenshot = ImageGrab.grab(bbox=(left, top, right, bottom))
screenshot.save(img_path)
return screenshot
def screenshot_orc(img_path):
ocr = PaddleOCR(use_angle_cls=True, lang='ch', use_gpu=False,show_log=False) # 默认使用英文和中文识别
# 进行 OCR 文本识别
result = ocr.ocr(img=img_path, cls=True)
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
return boxes,txts
def gui_clieck(x,y,clicks=2):
p = pyautogui.position() # 获取鼠标当前位置
pyautogui.click(x,y,clicks=clicks)
pyautogui.moveTo(p.x,p.y) # 返回鼠标指针
def generate_random():
while True:
num = random.randint(60, 360)
if not (133 <= num <= 155 or 260 <= num <= 280):
return num
##### ------------- 微信小程序 向僵尸开炮 -------------
def find_skill_index(skill_to_find, skill):
# 遍历skill_to_find中的每个技能
for skill_needed in skill_to_find:
# 遍历skill列表中的每个元素
for index, skill_available in enumerate(skill):
# 检查skill_to_find中的元素是否存在于skill列表的某个元素中
if skill_needed in skill_available:
# 如果找到,返回当前skill的索引
return index
return None
jx_img_path = "./jiangshi.png"
count = 1
latest_data = []
while True:
time.sleep(1)
# 截图并保存 screenshotop
screenshot_from_monitor(left=0,top=40,right=410, bottom=800,img_path=jx_img_path)
# OCR识别 返回数据
boxes, txts = screenshot_orc(img_path=jx_img_path)
latest_data = txts
logging.info(f"当前运行的是第 {count} 次")
count += 1 # 更新计数器
## 开始游戏
if "开始游戏" in txts:
gui_clieck(200,660,2)
logging.info("开始游戏")
# 返回
elif "返回" in txts:
skill_to_find = ["返回"]
skill_index = find_skill_index(skill_to_find,txts)
gui_clieck(
boxes[skill_index][2][0],
boxes[skill_index][2][1]+45,2
)
logging.info("返回")
elif "精英掉落" in txts:
gui_clieck(200,400,2)
logging.info("精英关卡通过")
elif "领取" in txts:
gui_clieck(290,680,2)
gui_clieck(360,235,1)
logging.info("领取巡逻收益")
else:
if "选择技能" in txts:
# 技能优先排序定义
skill_to_find = [
"射击连发",
"子弹命中",
]
skill_index = find_skill_index(skill_to_find,txts)
if skill_index is not None:
gui_clieck(
boxes[skill_index][0][0]+10,
boxes[skill_index][0][1],2
)
logging.info("选择技能: " + txts[skill_index])
continue
else:
random_number = generate_random()
gui_clieck(random_number,444,2)
logging.info("未匹配上,随机选择")总结
代码方面时间有限,问题比较多
- 代码随意,偏过程
- 异常没处理
- 技能选择未记录,否则可做更优的选择判断,甚至接入AI帮你判断
- 封装不够。动作封装的足够的话,后续的小程序都可以自动化掉
- 循环截图识别,缺少判断条件
通过这个自动化小脚本的编写,对几个库有了一些了解,并能应用到实践中,还是有不少收获的。